[Python Series 1/n] Modern Python Package Management: pipx and uv for Data Scientists
This post is inspired by a conversation with a fellow Data Science and AI student. It’s from the conversation, co-authored with Claude. Hope it’s useful!
Were to begin?
When you’re starting your data science journey with Python, one of the first roadblocks you’ll encounter is package management. If you’ve tried conda and found it frustrating (as many do), you’re not alone. Let’s explore two modern tools that make Python package management simpler and more reliable: pipx and uv.
The Problem with Traditional Python Package Management
If you’ve used Python for any length of time, you’ve likely encountered some variant of:
ImportError: No module named 'something_you_just_installed'
Or perhaps the infamous “dependency hell” where installing one package breaks another. These issues stem from Python’s historical approach to package management, which wasn’t designed with today’s complex data science environments in mind.
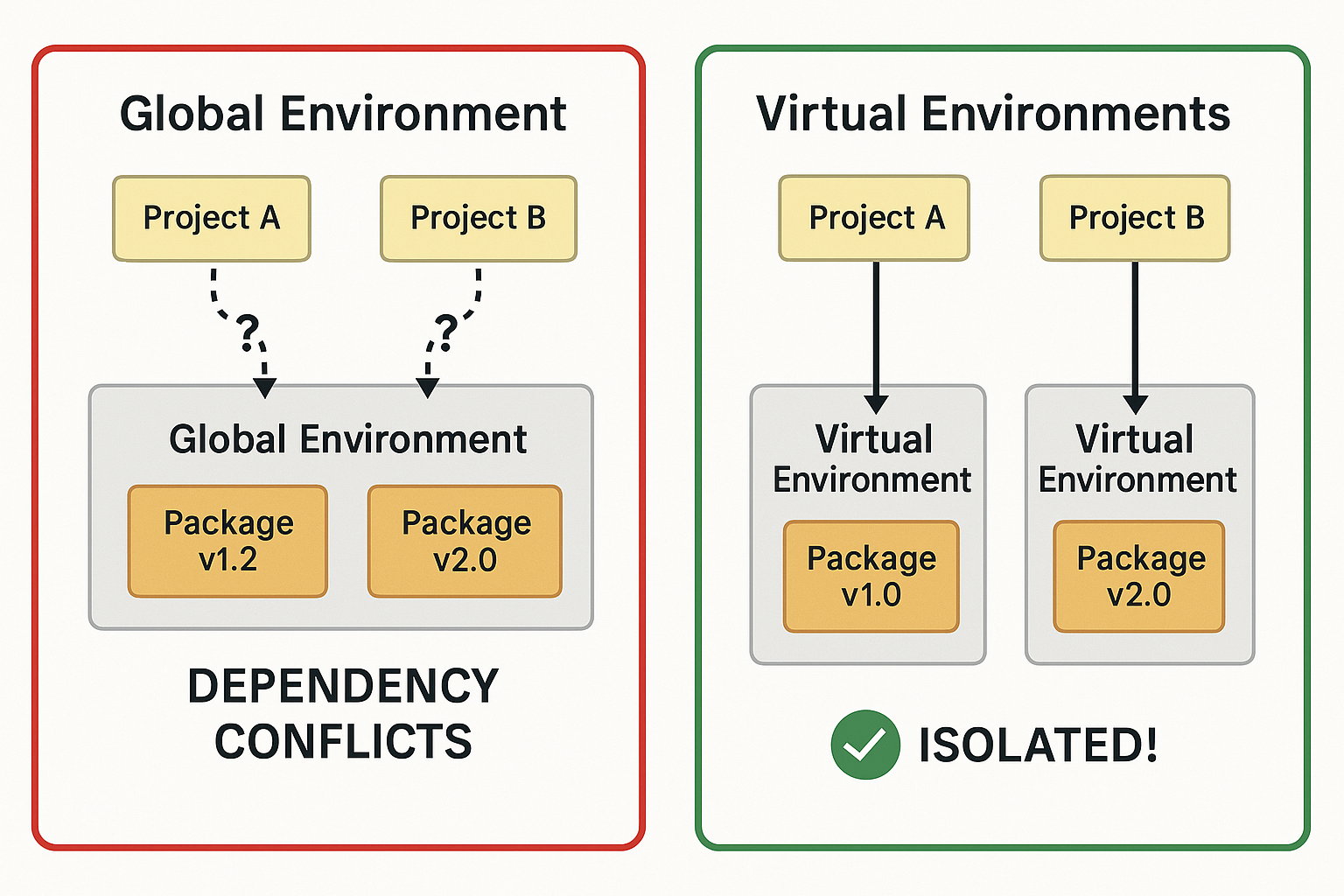
Traditional pip installs packages globally by default, which can lead to conflicts between projects that need different versions of the same library. Virtual environments solve this partially, but managing them adds complexity to your workflow.
Enter pipx and uv: Modern Solutions for Modern Problems
What is pipx?
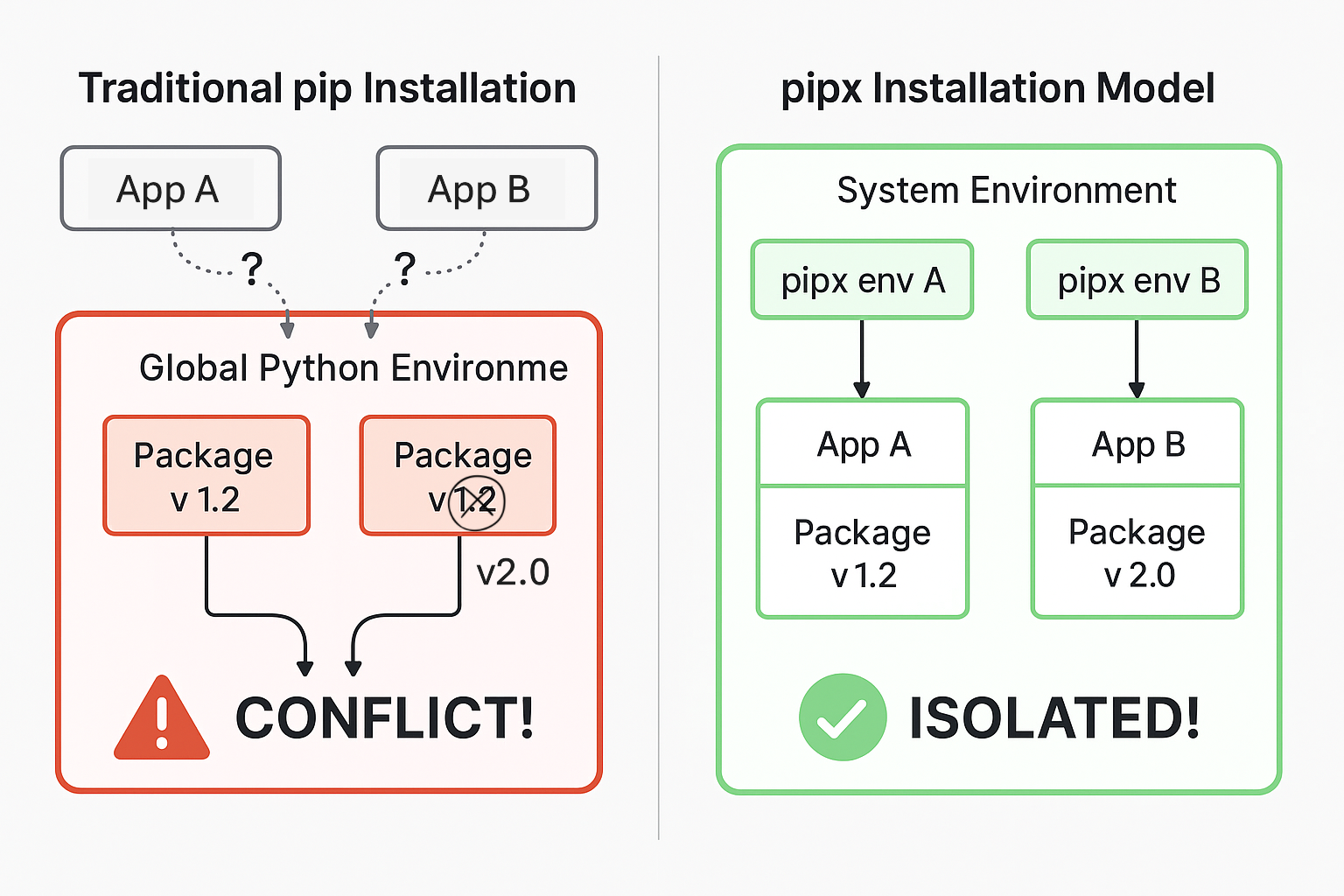
pipx is a tool that allows you to install and run Python applications in isolated environments. Think of it as “brew for Python applications” - it gives you the ability to run Python applications without worrying about dependencies or virtual environments.
The key insight behind pipx is separating applications from libraries. When you install Jupyter with pipx, for example, it creates a dedicated environment just for Jupyter and its dependencies, keeping them isolated from your other projects. In this blog we’ll use it for uv.
What is uv?
uv is a blazingly fast Python package installer and resolver written in Rust. It serves as a drop-in replacement for pip, but with significant advantages:
- It’s much faster (often 10-100x faster than pip)
- It has more reliable dependency resolution
- It creates reproducible builds by default
- It integrates seamlessly with virtual environments
Getting Started with pipx and uv
Let’s walk through setting these tools up and using them in a data science workflow.
Installing pipx
# On macOS or Linux or WSL2
brew install pipx
pipx ensurepath
# On Linux or WSL2
python3 -m pip install --user pipx
python3 -m pipx ensurepath
Using pipx for Applications
Now you can install Python applications globally without polluting your system Python:
# Install Jupyter
pipx install jupyter
# Install Black (code formatter)
pipx install black
# Run an application without installing it
pipx run httpie httpbin.org/json
This gives you command-line tools without cluttering your main Python environment.
Installing uv
The easiest way to install uv is through pipx:
pipx install uv
Using uv for Package Management
uv works with virtual environments just like pip, but much faster:
# Do not do this until you have read below!!
# Install packages with uv
uv pip install numpy pandas matplotlib scikit-learn
Creating an isolated Python environment.
Just like with applications, you can create an environment for your project that will not experience conflicts of package versions.
You can also use uv to create and manage virtual environments directly:
# Create venv and install packages in one command
uv venv
# Either install the packages directly
uv pip install numpy pandas matplotlib scikit-learn
# or install from a requirements.txt
uv pip install -r requirements.txt
Creating a Data Science Environment with uv
For data scientists, here’s a practical example of setting up a complete environment:
# Create a new project folder
mkdir my_ds_project
cd my_ds_project
# Create a virtual environment and activate it
uv venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
# Install common data science packages
uv pip install numpy pandas matplotlib seaborn scikit-learn jupyter
# Create a requirements.txt file with exact versions
uv pip freeze > requirements.txt
The resulting environment will be consistent and reproducible, with all packages installed at lightning speed.
Why This Matters for Data Scientists
As a data scientist, your focus should be on analyzing data and building models, not fighting with package managers. The benefits of using pipx and uv include:
- Speed: uv installs packages much faster than pip or conda, saving you time
- Isolation: pipx keeps your applications separate, preventing conflicts
- Reproducibility: uv’s dependency resolution ensures your environment can be exactly replicated
- Simplicity: These tools follow Python’s philosophy of “there should be one obvious way to do it”
Comparison with conda
Conda tries to solve similar problems but takes a different approach. While conda manages both Python and non-Python dependencies (like C libraries), it creates a separate ecosystem that can sometimes feel disconnected from the standard Python tooling.
Issues people often encounter with conda include:
- Slow resolution times for complex environments
- Conflicts between conda and pip when both are used
- Different behavior than standard Python tools
- Large installation size
In contrast, pipx and uv build upon the existing Python ecosystem rather than replacing it. They enhance what’s already there, making them more intuitive for those familiar with standard Python tools.
Conclusion
For data scientists new to Python, adopting pipx and uv can significantly reduce the friction of managing packages and environments. They provide a more modern, faster, and more reliable approach to package management without the overhead and complexity of conda.
In future posts, we’ll explore how to integrate these tools into specific data science workflows and how to handle advanced scenarios like working with packages that have complex dependencies.
Remember: your tools should serve your workflow, not the other way around. Free your brain to think about more novel tasks and ideas! 🤓✌🏼